
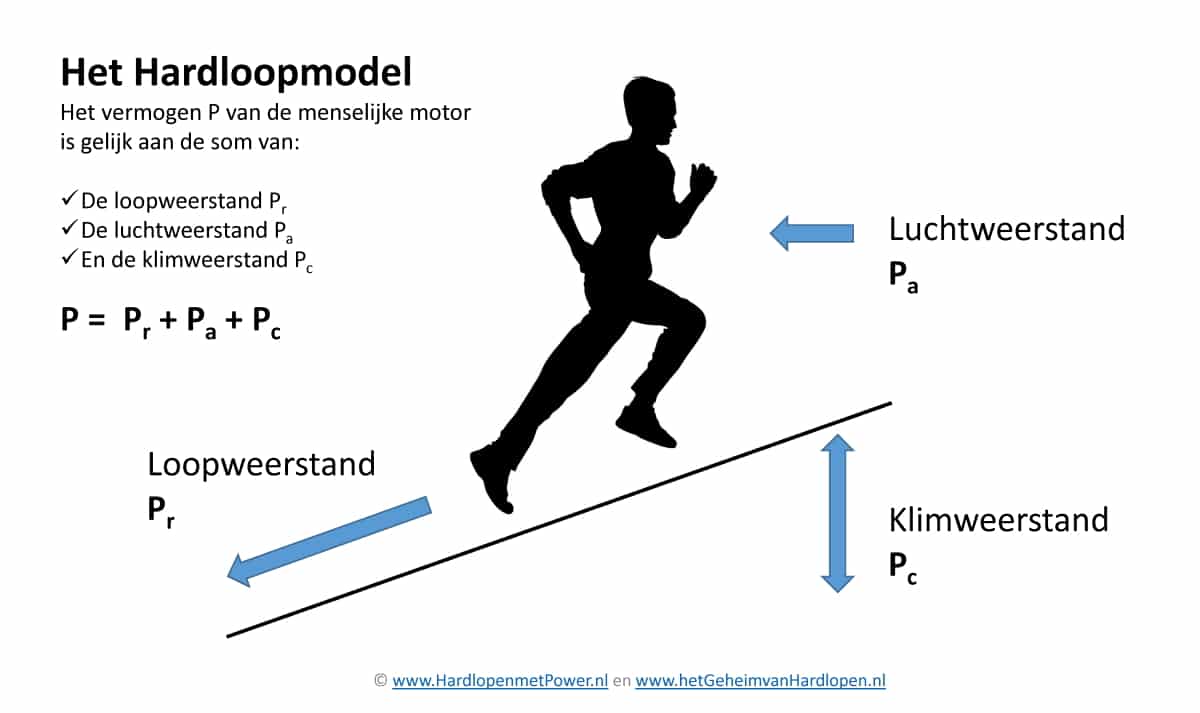
Innovaties van Polar
In 2019 verzocht Koen Demyttenaere van Polar ons om hun nieuwe Polar Vantage V horloge te testen. Dat vonden we heel interessant, temeer daar de Polar Vantage V ook je hardloopvermogen in Watt geeft. Onze bevindingen legden we vast in twee eerdere artikelen voor ProRun, deel 1 en deel 2. De Polar Grit X is het robuuste broertje van de Polar Vantage V.
Bij deze testen liepen we er tegenaan dat de vermogens die Polar rapporteert een stuk (orde 25-30%) hoger zijn dan de waarden van Stryd en die van ons natuurkundige hardloopmodel. We begrepen dit niet en vroegen Koen om nadere informatie over de achtergronden van hun algoritme. Op deze plaats willen we Polar complementeren over hun openheid hierbij. Via Koen kregen we contact met hun chief scientist uit Finland, dr. Jussi Peltonen, hetgeen leidde tot een hele goede inhoudelijke discussie. We kregen ook een intern white paper over de achtergronden van de in de software geprogrammeerde hardloopvermogensberekening.
Dit alles leidde ertoe dat we tot een duidelijke conclusie konden komen waar het verschil van 25-30% door veroorzaakt wordt. Polar rapporteert het bruto vermogen (gebaseerd op metingen met krachtplaten) en Stryd rapporteert het netto vermogen (gebaseerd op metingen van het netto zuurstofverbruik bij hardlopen). Het verschil tussen beiden is de elastische energieterugwinning in je Achillespees en de spieren van je onderbeen bij de landing van je voet op de grond.
Op zich zijn beide methoden valide.
Omdat je hardloopprestatie vooral bepaald wordt door je zuurstofverbruik geven wij de voorkeur aan het netto vermogen. In ons hardloopmodel werken we ook met het netto vermogen dat nodig is voor het overwinnen van de loopweerstand, de luchtweerstand en de klimweerstand.
Recent wees Polar ons op een nieuw onderzoek waarbij geanonimiseerde Big Data werd geanalyseerd. Jussi Peltonen heeft hier samen met een onderzoeker van de universiteit van Parijs een baanbrekend artikel over geschreven. Hieronder geven we een samenvatting van het idee achter Big Data en de resultaten van het onderzoek van Thorsten Emig en Jussi Peltonen.
Wat is het idee achter Big Data?
Vanouds werd het onderzoek en de kennis over hardlopen vooral gebaseerd op fysiologische testen in het laboratorium. Hierbij werden en worden parameters als het maximale zuurstofverbruik (de VO2 max in ml/kg/min), de lactaatdrempel en de Running Economy (het zuurstofverbruik per km in ml/kg/km) bepaald van kleine aantallen lopers op een loopband.
Aanvullend wordt ook gekeken naar het uithoudingsvermogen, zoals het percentage van het VO2 max dat volgehouden kan worden gedurende langere tijd. Dergelijk onderzoek heeft het voordeel dat onder nauwkeurige condities specifieke hypotheses wetenschappelijk kunnen worden getest. Nadelen zijn onder meer dat het onderzoek beperkt is tot kleine testgroepen en de prestatie in de praktijk mede bepaald wordt door zaken als het weer, het parcours en de vorm van de dag.
In de afgelopen decennia hebben we een enorme groei gezien van het gebruik van sporthorloges en andere draagbare sensoren. Inmiddels worden hiermee jaarlijks meer dan 1 miljard trainings-en wedstrijdsessies wereldwijd vastgelegd op diverse platforms als Strava, Garmin, Stryd, Polar enzovoort.
In principe biedt deze “Big Data” een geweldige kans om fysiologische informatie niet-invasief te monitoren onder real-world condities buiten het laboratorium. Dit kan leiden tot nieuwe inzichten en kennis over het effect van training en wedstrijden op grote delen van de bevolking, variërend van joggers tot topatleten. In principe zijn de mogelijkheden eindeloos, denk aan optimalisatie van trainingsprogramma’s, het nauwkeurig voorspellen van wedstrijdtijden, de (positieve) gezondheidseffecten van fysieke training, het vroegtijdig ontdekken van blessures of overtraining, het vroegtijdig ontdekken van talenten en zelfs het effect van ‘performance enhancers’, waaronder ook schoentechnologie.
Wij zijn ervan overtuigd dat we nog maar aan het allereerste begin van het gebruik van Big Data staan en dat de komende jaren de kennis over hardlopen in een stroomversnelling zal komen. We verwachten dus zeker dat Big Data ons in de toekomst zal helpen om sneller (en gezonder) te worden.
Wat kan er nu al? : het onderzoek van Emig en Peltonen
Emig en Peltonen hebben een analyse gemaakt van de gegevens van 19.000 mensen die in totaal 35 miljoen km hardgelopen hebben in 3,5 jaar. De gegevens zijn afkomstig van Polar V800 horloges en het Polar Flow platform. Vergeleken met de vele miljoenen gebruikers van sporthorloges, is dit dus nog een beperkte eerste stap in het gebruik van Big Data. In totaal zijn 25.000 wedstrijdseizoenen geanalyseerd. De gemiddelde afstand per sessie was 12,9 km en het totale aantal wedstrijden was 85.000.
De belangrijkste resultaten waren:
- Nauwkeurigheid van het voorspellen van wedstrijdtijden
Hun model bleek een nauwkeurigheid te geven van 2% voor ‘gewone’ wedstrijden en 10% voor de marathon. Bij de marathon spelen uiteraard weersomstandigheden en parcours een grotere rol, die met hun model ook niet te voorspellen is.
- Het effect van training
Dit is het meest interessante deel van het onderzoek. Ze hebben gekeken naar 3 aspecten:
- de invloed van het trainingsvolume (afgelegde km’s)
Zij vonden een statistisch significante positieve lineaire relatie tussen het aantal afgelegde trainingskilometers en de haalbare snelheid vm (dit is de snelheid bij de VO2 max), zoals weergegeven in onderstaande figuur uit het artikel van Emig en Peltonen. Deze positieve relatie is in overeenstemming met de literatuur.
Hun hypothese is dat dit komt door verbetering van de Running Economy. Met andere woorden de lopers gaan zuiniger lopen door duurtraining. Helaas kan op basis van de data een andere verklaring niet uitgesloten worden, namelijk dat fittere lopers (met een hogere vm) meer kilometers trainen.

- de invloed van de intensiteit (percentage van maximale snelheid)
Hier vonden ze een negatieve relatie tussen de trainingsintensiteit en de haalbare snelheid vm, zoals weergegeven in de onderstaande figuur. Dit is eveneens in overeenstemming met de literatuur die stelt dat bij duurtraining een groot percentage op lage snelheid moet worden gelopen.
De resultaten kunnen dus verklaard worden door aan te nemen dat fitte lopers dit trainingsadvies opvolgen. Helaas kan op basis van de data een andere verklaring niet worden uitgesloten, namelijk dat het horloge tijdens een rustdeel van de training niet stopgezet is.

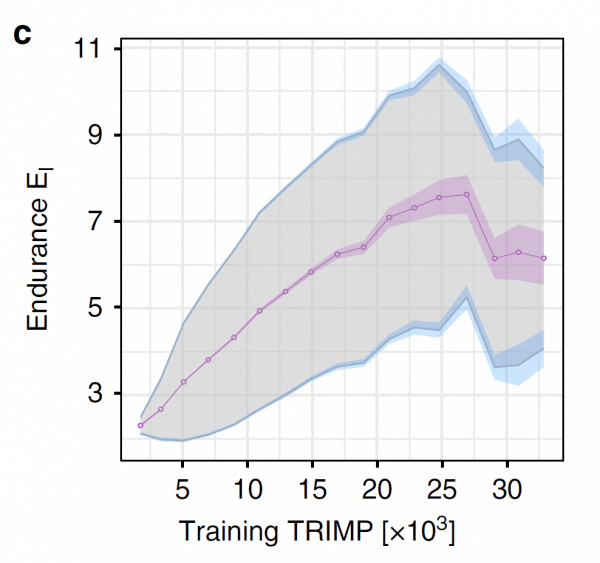
- het gecombineerde effect van omvang en intensiteit (uitgedrukt in TRIMP, training impulse, een combinatie van afgelegde km’s en percentage van maximale snelheid)
Hier vonden ze een zeer interessant resultaat, namelijk dat het uithoudingsvermogen (uitgedrukt in een factor El) lineair toeneemt met TRIMP, maar vanaf 25.000 weer afneemt, zoals weergegeven in de onderstaande figuur. Dit laatste zou een indicatie kunnen zijn van overtraining.
Conclusies
We verwachten dat Big Data ons op termijn zeker zal kunnen helpen om sneller (en gezonder) te worden. De enorme hoeveelheden data die wereldwijd geüpload worden naar platforms als Strava, Garmin, Stryd, Polar en dergelijke vormen een potentiële goudmijn om het inzicht en de kennis over hardlopen en trainingsmethoden te vergroten en de prestatie van hardlopers te optimaliseren.
Het onderzoek van Emig en Peltonen moet in dit perspectief bezien worden. Het is een eerste aanzet tot het analyseren van Big Data om ons te helpen beter te gaan lopen. Uit de besproken resultaten blijkt ook dat het zeker niet eenvoudig is om deze Big Data te vertalen naar nuttige kennis en inzichten. Problemen bij de interpretatie van de resultaten zijn onder meer:
- de data zelf kunnen vervuild zijn (is het horloge wel stopgezet tijdens de rust?)
- de invloed van het weer en het parcours kan het beeld vertroebelen
- de grote individuele verschillen tussen lopers onderling kan het lastig maken om universele conclusies te trekken
- een correlatie is nog geen bewijs van een causaal verband: zo kan training met een hogere TRIMP leiden tot een beter uithoudingsvermogen El , maar omgekeerd is het ook mogelijk dat lopers met een hoger uithoudingsvermogen El beter in staat zijn om te trainen met een hogere TRIMP
Toch mogen we verwachten dat in de toekomst deze en andere problemen opgelost gaan worden zodat Big Data ons echt kan helpen om beter te gaan lopen.
Stryd heeft in dit opzicht een veelbelovend concept ontwikkeld met het Stryd Power Center. Sterke punten van dit concept zijn het feit dat het gebaseerd is op vermogen (waardoor in principe de invloed van het weer en het parcours meegenomen kunnen worden) en dat iedere loper zijn eigen data verwerkt krijgt in zijn persoonlijke Power Duration Curve (zodat de grote individuele verschillen tussen lopers het beeld niet vertroebelen).
Kortom: wij zien uit naar een toekomst met Big Data (voor het lopen dan, waarbij we ons over de privacy niet zo druk maken).




Leo Van den Wyngaert
Graag wat meer uitleg over TRIMP:
– Wat is Vmax? Is dit bij de Aërobe drempel of max spurtsnelheid?
– Wat is omvang in km? 6 maanden voorbereiding of 3 maanden voorbereiding of …
RunHanRun.nl
Wat een mooie informatie! Valt vast nog wel veel meer uit te halen. En die anomalieën mbt wel/niet stopzetten van het horloge tijdens rust of juist run, zullen worden genihileerd vanwege het grote aantal gegevens.
Los daarvan, dat valt toch ook uit te lezen uit de data….?